In the last post, I talked about two issues that affect surface texturing on mobile devices. Mobile GPUs tend to have a smaller floating point precision than their desktop cousins, which limits the range of our texture coordinates, and less power, which limits the complexity of our fragment shaders. Next, I’d like to address two issues that are less specific to mobile GPUs, but make a big difference in the final framerate.
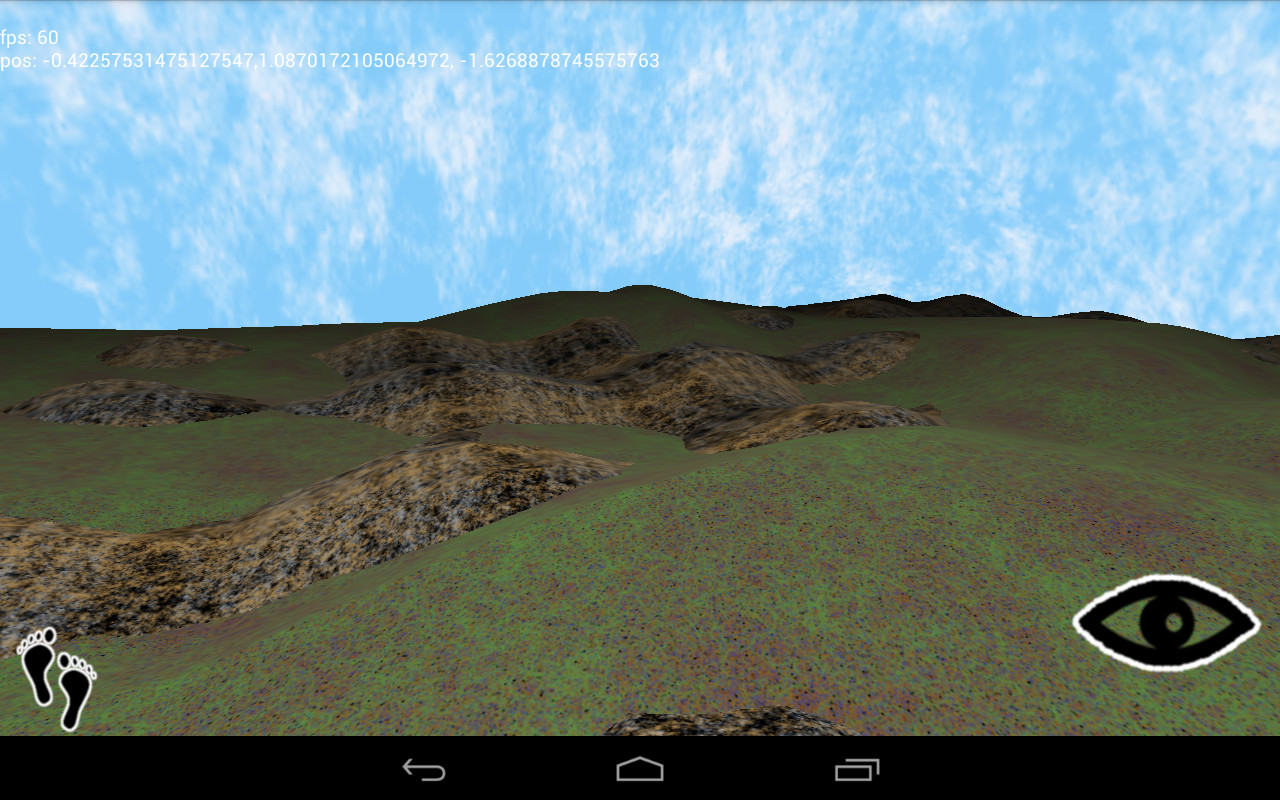
When drawing multiple intersecting surfaces—a landscape with rocks and hills, for example—it’s tempting to ignore overdraw, a condition where areas of the screen can be painted over multiple times. Modern GPUs are fantastic at eliminating hidden surfaces within a single drawcall, and hardware depth-testing avoids this problem across multiple drawcalls. So it seems silly to worry about. Just draw everything, right?
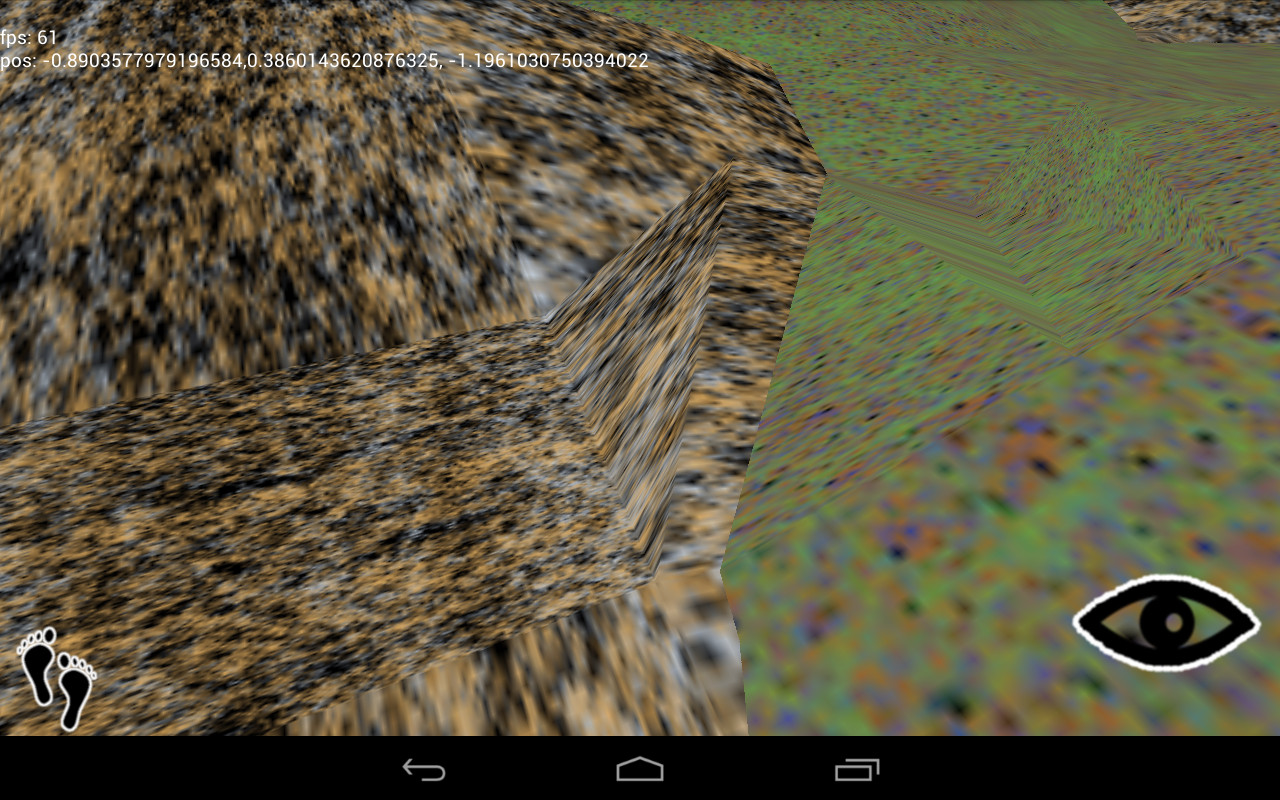
However, complex scenes can still cause trouble. I find that drawing one object in front of another doesn’t cause a performance hit, but when two surfaces intersect such that each is partially inside the other, the resulting complexity bogs the GPU down.
In my current game project, I’m using scalar fields to represent (and generate) all surfaces (see my previous posts on this subject), which makes collision detection easy. To see if a point lies within a surface, I check the field value at the point. To see if a polygon falls within the surface, I check each vertex in turn.
/**
* determines if a polygon is entirely inside the isosurface
* @param v0, v1, v2 vertexes of the polygon
* @return true if polygon is inside
*/
public boolean inside(Vector v0, Vector v1, Vector v2) {
return getField(v0.x, v0.y, v0.z)
Happily, this provides a simple solution to the overdraw problem. I can easily test whether a polygon is contained by any surface other than its owner.
/**
* determines if a polygon will intersect multiple surfaces
*
* @param self calling object
* @param v0, v1, v2 vertexes of the polygon
* @return true if polygon intersects multiple surfaces
*/
public boolean mayOverdraw(Base self, Vector v0, Vector v1, Vector v2) {
if (self != ground && ground.inside(v0, v1, v2))
return true;
if (self != stone && stone.inside(v0, v1, v2))
return true;
if (self != rocks && rocks.inside(v0, v1, v2))
return true;
return false;
}
When building the surface, I reject any polygon that fails the test.
/**
*
* polygonization superclass
*
*/
class ASurfacer extends Surfacer {
public double field(double x, double y, double z) {
return getField(x, y, z);
}
public void build(Vector v0, Vector v1, Vector v2, Vector n) {
// reject polygons inside other surfaces
if (!world.mayOverdraw(caller, v0, v1, v2))
handlePolygon(v0, v1, v2, n);
}
}
In my current game project, using this technique bumped the frame rate from 40 to 50. It also prevented sudden dips in frame rate caused by multiple intersecting surfaces in the scene.
If you're generating heightmaps, indexing your polygons is a no-brainer. It's easy to map integers to the points of a 2D grid. When I started working with arbitrary surfaces and marching cubes, this was the method I came up with.
// callback for building surface mesh
function polycb(p) {
gradient(n, p.x, p.y, p.z);
var key = Math.floor(p.x * 100) + "." + Math.floor(p.y * 100) + "." + Math.floor(p.z * 100);
var ent = hash[key];
if (ent !== undefined) {
mesh.index(ent);
} else {
mesh.set(p.x, p.y, p.z, n.x, n.y, n.z);
mesh.index(indx);
hash[key] = indx++;
}
}
It works, but relies on a truly cringeworthy key generation formula (note to past self: just because you can discard precision doesn't mean you should), as well as having a fast hashing algorithm under the covers. When I ported this to Android, the results were less than stellar, and I had to find a better approach.
/**
* Index generator for 3D vertexes
*
* implements an octree in a fixed-size array;
* as the mesh object only allows short ints
* to be used for indexes, we don't bother to
* make the array length > 64k
*
* @author chris
*
*/
public class Vindexer {
static public final int INDEX_MASK = 0xFFFF;
static public final int ADD_VERTEX= 0xFFFF0000;
static private final int MAX_INDEX = 65536;
static private final float MIN_LIMIT = 0.0001f;
private float[] vertex;
private int[] child;
private int length;
private int hits;
/**
* constructor, generates fixed array
*/
public Vindexer() {
vertex = new float[3 * MAX_INDEX];
child = new int[8 * MAX_INDEX];
reset();
}
/**
* call prior to generating new indexes
*/
public void reset() {
length = 0;
hits = 0;
}
/**
* check that a specific vertex is in the octree,
* create it if it isn't. either way, return the
* index of the vertex.
*
* if the indexer hasn't seen this vertex yet, I
* assume the calling code needs to add it to a
* vertex buffer, so the ADD_VERTEX flag is ORed
* with the index. typically, you'd do something
* like this:
*
* int result = vindexer.check(x, y, z);
* int index = result & Vindexer.ADD_VERTEX
* if (index != result) {
* // add vertex to buffer
* vertexbuffer.set(x, y, z);
* }
* indexbuffer.set(index);
*
*
* @param x, y, z coordinates of vertex
* @return index of new or stored vertex, maybe ORed with
* ADD_VERTEX if new vertex (see above)
*/
public int check(float x, float y, float z) {
int vin, cin, index = 0;
while (index vx) ? 4 : 0) + ((y > vy) ? 2 : 0) + ((z > vz) ? 1 : 0);
if (child[ch] != -1) {
index = child[ch];
} else {
child[ch] = (int)length;
index = length;
}
}
// no entries found, create one
vin = length * 3;
cin = length * 8;
vertex[vin] = x;
vertex[vin + 1] = y;
vertex[vin + 2] = z;
for (int i = 0; i = MAX_INDEX) {
throw new RuntimeException("Vindexer exceeded index limits");
}
// return index with "add vertex" flag in upper word
return index | ADD_VERTEX;
}
}
Implementing an octree using fixed arrays might be considered a criminal offense in some jurisdictions, but I thought it made sense here for two reasons. First, generating a mesh large enough to require indexes greater than 65536 isn't recommended practice for desktops, let alone mobile GPUs, so I felt justified in setting an upper limit. Second, I find that in garbage-collected environments, it's best to throw away as little as possible. The conventional node-based octree implementation would have required throwing out thousands of objects on every surface generation pass. (Remember, I'm generating this stuff in real time, not pulling it from a model file.) Less garbage means fewer collections, and less frame stuttering.
Indexing the surfaces increased the frame rate from 50 to 60, and that's as high as it goes. There aren't too many "massive" framerate optimizations out there, once you eliminate the obvious (don't draw 100 million vertexes), but following a few simple rules of thumb will pay big dividends.